10월 22일 인트로 복습용 정리
Comet (by Perplexity)
- 퍼플렉시티에서 만든 웹 기반 정보 수집형 AI 도구
- 검색+분석+요약을 한번에 해주는 AI 리서치 어시스턴트

에이전트 모드 v. 바이브 코딩
| 구분 | 개념 | 목적 |
| 에이전트 모드 | AI가 "목표 지향적 행동"을 스스로 수행하는 모드 | 사용자가 명령을 주면, AI가 스스로 계획·탐색·실행을 함 |
| 바이브 코딩 | 인간과 AI가 "함께 코드를 완성"하는 협업형 코딩 | 사용자는 아이디어·컨셉을 말하고, AI가 지시에 맞춰 코드나 구조를 제시 |
- 에이전트 모드 : AI가 스스로 "작업 단계를 설계하고 실행"하는 자동 모드
- 바이브 코딩 : 사람과 AI가 실시간으로 "공동 제작"하는 코딩 협업 방식
CPA 예측을 위한 선형회귀 및 잔차분석
- CPA (Cost Per Action) : 사용자가 광고를 보고 특정 행동(회원가입, 구매, 클릭 등)을 완료했을 때 발생하는 행동당 비용
- CPA 예측 모델 목표
- 주어진 광고 지표(CTR, CPM, Conversion 등)로 향후 CPA를 예측
- 효율적인 예산 집행 및 채널 전략 수립
- 고비용 캠페인을 사전에 식별
→ 이 과정에서 가장 기본이 되는 모델이 선형회귀이며, 모델의 타당성을 평가하기 위해 잔차분석을 수행
1. CPA의 정의와 의미

2. 예측 문제로의 전환
목표 : CPA를 예측하는 회귀모델 구축
| 변수명 | 설명 |
| CTR | Click Through Rate (클릭률, %) |
| Conversion Rate | 클릭 대비 전환율 |
| CPM | 1,000회 노출당 비용 (원) |
| Budget | 광고 예산 (원) |
| CPA | 행동당 비용 (타겟 변수, 예측 대상) |
3. 선형회귀 기본 개념
- 입력 변수(X)가 출력값(Y, CPA)에 미치는 선형 관계(Linear Relationship)를 학습하는 모델
- 목표 : 잔차(residual)를 최소화하는 b를 찾는 것 (*잔차 = 실제 - 예측)

4. 과정 연습
1. 캠페인 데이터 준비
import pandas as pd
data = {
"Campaign": ["A","B","C","D","E","F","G","H","I","J"],
"CTR": [1.2, 0.9, 1.5, 1.0, 0.8, 1.3, 1.1, 1.4, 0.95, 1.0],
"Conversion": [0.18, 0.15, 0.22, 0.19, 0.14, 0.21, 0.17, 0.24, 0.16, 0.18],
"CPM": [5300, 4800, 7200, 5100, 4500, 6700, 5500, 7000, 4900, 5000],
"Budget": [100000, 85000, 120000, 95000, 80000, 115000, 90000, 125000, 85000, 90000],
"CPA": [2100, 2300, 1900, 2050, 2400, 1950, 2200, 1850, 2250, 2150]
}
df = pd.DataFrame(data)
2. 선형회귀 모델 학습
from sklearn.linear_model import LinearRegression
X = df[["CTR", "Conversion", "CPM", "Budget"]]
y = df["CPA"]
model = LinearRegression()
model.fit(X, y)
print("회귀계수:", model.coef_)
print("절편:", model.intercept_)- CTR, Conversion Rate가 높을수록 CPA는 낮아짐 (효율 개선)
- CPM과 Budget이 높을수록 CPA는 소폭 상승 (비용 증가 영향)
3. 예측 및 성능 평가
from sklearn.metrics import r2_score, mean_absolute_error
y_pred = model.predict(X)
r2 = r2_score(y, y_pred)
mae = mean_absolute_error(y, y_pred)
print("결정계수 R²:", round(r2,3))
print("평균절대오차 MAE:", round(mae,2))- 모델이 CPA 변동의 약 98%를 설명함
- 평균 예측오차는 약 17.45원 수준으로 우수한 예측력
5. 잔차분석 (Residual Analysis)
- 모델이 제대로 작동하는지 확인하기 위한 핵심 과정
- "예측된 CPA와 실제 CPA 간 차이(잔차)가 패턴 없이 랜덤한가?"를 검증
🔎 잔차분석
| 구분 | 확인 목적 | 이상적 모습 |
| 선형성(Linearity) | 예측값과 실제값의 관계가 선형인가? | 잔차가 0을 중심으로 랜덤하게 흩어져야 함 |
| 등분산성(Homoscedasticity) | 모든 구간에서 오차 크기가 일정한가? | 예측값이 커져도 잔차의 퍼짐이 일정해야 함 |
| 독립성(Independence) | 잔차 간의 상관이 없는가? | 시간순으로 패턴이 없어야 함 |
| 정규성(Normality) | 잔차가 정규분포를 따르는가? | Q-Q plot에서 대각선 근처에 점이 모여야 함 |
1. 잔차 : 예측이 빗나간 정도
(예) 학생의 시험 점수를 '공부 시간'으로 예측하는 모델 생성
- 모델은 “10시간 공부하면 90점일 것”이라고 예측했는데, 실제 점수는 85점이었다면?
- 잔차 = 실제값 - 예측값 = 85 - 90 = -5점 즉, 모델이 5점만큼 과대 예측한 것
→ 모든 데이터마다 이런 "오차(잔차)"가 생기고, 잔차를 모아 보면 모델의 문제점을 확인할 수 있음
2. 마케팅 데이터 연결 포인트
(예) 광고비로 '클릭수'를 예측하는 회귀모델 생성
- 잔차가 패턴 없이 고르게 분포한다면 → "광고비로 클릭수 예측이 잘 되고 있다"
- 잔차가 한쪽으로 몰리거나 퍼짐이 커진다면 → "예산이 높을 때 다른 요인이 영향을 주고 있다"
→ 실무에서는 이 과정을 통해 "다른 변수 추가"나 "모델 교체(비선형 회귀, 로그 변환 등)"를 결정할 수 있음
import matplotlib.pyplot as plt
import numpy as np
residuals = y - y_pred
plt.figure(figsize=(7,5))
plt.scatter(y_pred, residuals)
plt.axhline(y=0, color='red', linestyle='--')
plt.title("잔차분석: 예측값 vs 잔차")
plt.xlabel("예측 CPA")
plt.ylabel("잔차 (실제 - 예측)")
plt.grid(True)
plt.show()

정상적인 모델일 경우,
- 잔차들이 0 근처에 무작위로 분포해야 함
- 특정 방향(곡선 패턴 등)이 나타나면 비선형성 존재

| 구분 | 모양 | 의미 |
| 자기상관 없음 | 위아래로 불규칙하게 요동 | 잔차들이 독립적 → 회귀모형 가정 만족 |
| 자기상관 있음 | 위로 쭉 가거나 아래로 쭉 가는 구간 존재 | 잔차들이 시간적으로 연결 → 자기상관 존재 |
- 잔차 그래프에서 오차가 일정한 방향으로 이어져 나타나면 자기상관이 있는 것, 들쭉날쭉 불규칙하게 보이면 자기상관이 없는 것
- 자기상관이 있으면 잔차들이 서로 연결되어 모델이 시간적 패턴을 반영하지 못하고 결과적으로 통계적 검정과 예측의 신뢰성 하락
6. 잔차 분포 확인 (정규성 검정)
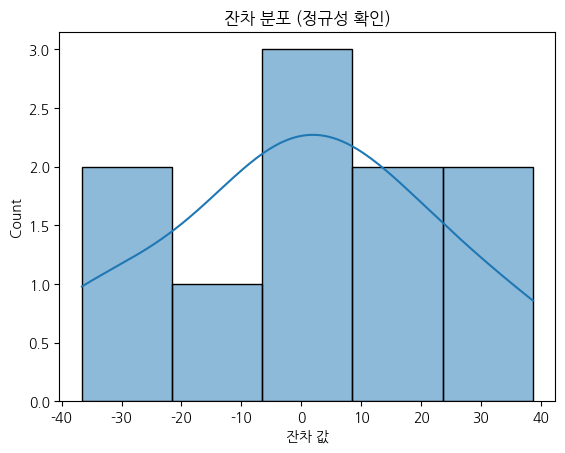

- 잔차 히스토그램이 종형(정규분포)에 가깝다면 → 모델 적합
- Q-Q Plot에서 점들이 직선 위에 있다면 → 잔차의 정규성 확보
7. 잔차의 자기상관 (Durbin-Watson Test)
from statsmodels.stats.stattools import durbin_watson
dw = durbin_watson(residuals)
print("Durbin-Watson 통계량:", round(dw,2))Durbin-Watson 통계량: 2.58- DW ≈ 2 → 자기상관 없음 (이상적)
- DW < 1.5 → 잔차가 양의 자기상관 (패턴 존재 가능성)
- DW > 2.5 → 음의 자기상관
🔎 Durbin-Watson 자기상관 검정
= 회귀모델의 오차항(잔차)들이 서로 독립적인지(autocorrelation이 없는지) 확인하는 검정
→ "이전 데이터의 오차가 다음 데이터의 오차에 영향을 주고 있지는 않은가?"를 확인하는 방법
- 회귀분석은 기본 가정 중 하나가 오차항끼리 서로 독립(independent)되어 있다는 것
- 만약 오차가 서로 연관되어 있다면 (=자기상관이 있다면)
- 모델이 “패턴을 놓치고 있다”는 뜻
- 예측이 체계적으로 한쪽으로 치우치거나 시계열적 패턴이 남아 있음
검정 결과 해석.
| DW 값 | 해석 | 의미 |
| ≈ 2 | 정상 | 오차 간 자기상관 없음 |
| < 2 (1 이하) | 양의 자기상관 | 이전 오차가 다음 오차에 비슷하게 영향 줌 |
| > 2 (3 이상) | 음의 자기상관 | 이전 오차가 다음 오차에 반대 방향으로 영향 줌 |
예시.
- DW = 2.05 → 정상
- DW = 1.2 → 약한 양의 자기상관 (모델 편향 가능성)
- DW = 2.8 → 약한 음의 자기상관
8. 변수 중요도 시각화

- 음수 계수(CTR, Conversion)는 CPA 절감에 기여
- 양수 계수(CPM, Budget)는 CPA 상승 요인
→ 즉, 클릭률과 전환율 개선이 CPA 절감의 핵심 레버리지
9. 선형모델 한계와 잔차 해석
| 문제 현상 | 잔차 패턴 | 원인 | 해결 방법 |
| 비선형 관계 | 곡선 패턴 | CTR·CPA 간 관계가 비선형 | 다항 회귀, 로그변환 |
| 이분산성 | 잔차 분포가 퍼짐 | 고비용 캠페인일수록 오차 커짐 | 로그스케일링, 가중회귀 |
| 이상치 영향 | 특정 잔차가 매우 큼 | 비정상 캠페인 데이터 존재 | Robust 회귀, 이상치 제거 |
| 누락 변수 | 잔차가 특정 방향으로 쏠림 | 설명변수 부족 | 추가 KPI 도입 (예) CPC, Impressions |
10. 마케팅 실무 해석 요약
| 분석 항목 | 해석 |
| CTR, Conversion Rate | 높을수록 CPA 감소 (효율 향상 요인) |
| CPM, Budget | 높을수록 CPA 증가 (비용 압박 요인) |
| R² | 모델의 예측 신뢰도 (0.9 이상이면 우수) |
| 잔차 패턴 | 랜덤 → 정상모델, 패턴 → 변수 누락 또는 비선형성 |
| Durbin-Watson | 2 근처면 정상, 1.5 이하이면 잔차 자기상관 의심 |
11. 캠페인 전략적 활용 방안
| 활용 영역 | 적용 방식 | 기대 효과 |
| 성과 예측 | 향후 CPA를 예측하여 예산 효율 추정 | 예산 낭비 최소화 |
| 성과 시뮬레이션 | CTR/전환율 가정값 입력으로 CPA 예상 | 최적 광고 조합 도출 |
| 성과 이상탐지 | 잔차가 큰 캠페인을 이상치로 식별 | 비정상 캠페인 조기 탐지 |
| ROI 최적화 | CPA 예측값으로 광고별 ROI 계산 | 투자 대비 성과 극대화 |
요점 정리
- 선형회귀 : KPI 기반 CPA 예측의 출발점으로 단순하지만 강력함
- 잔차분석 : 모델의 적합성·신뢰성·이상치 여부를 진단하는 핵심 과정
- CPA 모델은 단순 예측을 넘어 성과 해석 및 전략적 의사결정 도구로 활용 가능
- 고급 단계에서는 다항회귀, Ridge/Lasso, Gradient Boosting, Bayesian Regression 등으로 확장 가능
연습. CPA 예측 및 잔차분석
1. 라이브러리 불러오기
# 기본 분석 및 시각화 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 머신러닝 관련
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_absolute_error
from statsmodels.stats.stattools import durbin_watson
import scipy.stats as stats
2. 캠페인 성과 데이터
# 실제 마케팅 데이터처럼 하드코딩된 예시
data = {
"Campaign": ["A","B","C","D","E","F","G","H","I","J"],
"CTR": [1.2, 0.9, 1.5, 1.0, 0.8, 1.3, 1.1, 1.4, 0.95, 1.0],
"Conversion": [0.18, 0.15, 0.22, 0.19, 0.14, 0.21, 0.17, 0.24, 0.16, 0.18],
"CPM": [5300, 4800, 7200, 5100, 4500, 6700, 5500, 7000, 4900, 5000],
"Budget": [100000, 85000, 120000, 95000, 80000, 115000, 90000, 125000, 85000, 90000],
"CPA": [2100, 2300, 1900, 2050, 2400, 1950, 2200, 1850, 2250, 2150]
}
df = pd.DataFrame(data)
3. 데이터 관계 시각화

4. 선형회귀 모델 학습
X = df[["CTR", "Conversion", "CPM", "Budget"]]
y = df["CPA"]
model = LinearRegression()
model.fit(X, y)
print("회귀계수:", model.coef_)
print("절편:", model.intercept_)
5. 예측 및 성능 평가
y_pred = model.predict(X)
r2 = r2_score(y, y_pred)
mae = mean_absolute_error(y, y_pred)
print("결정계수 R²:", round(r2,3))
print("평균절대오차 MAE:", round(mae,2))
6. 예측값 v. 실제값 시각화

7. 잔차 계산 및 시각화

8. 잔차 분포 (정규성 확인)


9. Durbin-Watson 자기상관 검정
dw = durbin_watson(residuals)
print("Durbin-Watson 통계량:", round(dw,2))
10. 변수 중요도 시각화

11. 모델 해석 요약
- CTR, Conversion Rate : 높을수록 CPA 감소 (효율적 광고)
- CPM, Budget : 높을수록 CPA 증가 (비용 압박)
- R² : 0.9 이상이면 높은 설명력을 가지고 있음, 모델 신뢰도 높음
- 잔차분포 : 랜덤 분포 → 정상모델
- Durbin-Watson : 2 근처 → 자기상관 없음
- MAE (오차) : ± 50원 이내 → 매우 양호한 예측력
12. 실무적 활용 예시
| 활용 시나리오 | 활용 방식 | 기대 효과 |
| 광고 예산 시뮬레이션 | CTR·Conversion 가정치 입력 후 CPA 예측 | 효율적 예산 분배 가능 |
| 캠페인 이상탐지 | 잔차가 큰 캠페인 식별 | 비정상 성과 조기 탐지 |
| 채널별 효율 비교 | 회귀계수로 영향도 비교 | 주요 KPI 파악 가능 |
| ROI 분석 | 예측 CPA 기반 ROI 계산 | 투자 대비 효율 극대화 |
CPA를 위한 머신러닝 응용
- CPA(Cost Per Acquisition, 전환당 비용) 예측은 마케팅 퍼포먼스 분석에서 매우 핵심적인 문제
- 일반적인 클릭·노출 기반 예측보다 데이터의 불균형성과 시간적 변동성이 크기 때문에 신중한 모델 설계 필요
1. 문제 정의
- 목표 : 광고 캠페인별, 소재별, 혹은 일자별 CPA 예측
- 입력 변수
- 광고비, 노출수, 클릭수, 전환수
- CTR, CVR
- 광고소재 유형, 요일, 시간대, 플랫폼, 타겟 연령대 등
- 출력 변수 : CPA = 광고비 ÷ 전환수
2. 데이터 전처리 및 특징 엔지니어링
| 단계 | 내용 | 목적 |
| 이상치 처리 | 극단적인 광고비, 전환 0인 케이스 | 학습 안정화 |
| 로그 변환 | 광고비, 노출수 등 지수적 분포 변수 | 스케일 안정화 |
| 파생변수 생성 | CTR = Click/Impression, CVR = Conversion/Click 등 | 설명력 향상 |
| 카테고리 인코딩 | 광고소재유형, 요일, 디바이스 등 | 범주형 처리 |
| 시간변수 추가 | 시계열 흐름 반영 (예: 이전일 CPA, 주간 평균) | 트렌드 반영 |
3. 모델 제안
1. Baseline : 다중 선형 회귀 (Linear Regression)
- 장점 : 해석 용이, 빠른 학습
- 한계 : 변수 간 비선형 관계를 포착하기 어려움
- 적용 예시 : CPA = β₀ + β₁(광고비) + β₂(클릭수) + β₃(CTR) + ε
2. Gradient Boosting 기반 앙상블 모델
- XGBoost
- 과적합 방지와 결측치 자동처리 기능 우수
- 변수 중요도(Feature Importance)로 주요 요인 식별 가능
- LightGBM
- 대용량 로그 데이터에 적합 (속도 우수)
- 하이퍼파라미터 튜닝을 통한 최적화 용이
- CatBoost
- 범주형 데이터 자동 처리
- 광고소재나 타깃 그룹 등 카테고리 변수가 많을 때 효과적
3. 신경망 기반 모델
- MLP (다층 퍼셉트론)
- 입력 변수 간 비선형 상호작용 반영
- Dropout, Batch Normalization 적용으로 과적합 제어
- LSTM / GRU
- 시간 순서(시계열) 데이터일 경우 사용
- 과거 광고 성과가 다음날 CPA에 영향을 줄 때 적합
4. 혼합 접근 (Hybrid Model)
- 전략
- 트렌드(시계열) → LSTM
- 정적 변수(광고소재, 타깃 특성 등) → XGBoost
- 최종적으로 두 모델 출력을 Stacking Ensemble
4. 평가 지표
| 지표 | 설명 |
| MAE (Mean Absolute Error) | 예측 오차의 평균 절대값 |
| RMSE (Root Mean Squared Error) | 큰 오차에 더 큰 패널티 |
| R² (결정계수) | 모델 설명력 |
| MAPE (Mean Absolute Percentage Error) | 비율 기반 오차 평가 (CPA의 상대적 오차 측정에 유용) |
5. 실제 적용 시 고려사항
- 데이터 불균형 : 전환수가 0인 경우 많음 → SMOTE 등 샘플링 기법 사용
- 시간 민감성 : 최신 캠페인 반영 위해 rolling window 학습
- 모델 해석 : Shapley value 등으로 주요 요인(예: CTR, 광고소재, 요일별 영향) 분석
예제.
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
# 데이터 로드
df = pd.read_csv("ad_campaign_data.csv")
# 파생 변수
df["CTR"] = df["clicks"] / df["impressions"]
df["CVR"] = df["conversions"] / df["clicks"].replace(0, 1)
df["CPA"] = df["spend"] / df["conversions"].replace(0, 1)
# 특징, 타깃 분리
X = df[["spend", "impressions", "clicks", "CTR", "CVR"]]
y = df["CPA"]
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = lgb.LGBMRegressor(num_leaves=31, learning_rate=0.05, n_estimators=200)
model.fit(X_train, y_train)
# 평가
y_pred = model.predict(X_test)
print("MAE:", mean_absolute_error(y_test, y_pred))
print("R²:", r2_score(y_test, y_pred))
A. 레코드가 적을 때
MAE: 370.47617547898057
R²: -0.041407480317243506
B. 레코드가 많을 때
MAE: 13.819772344752245
R²: 0.8166816675354378
🔎 회귀모델 평가 지표 비교 (복습)
1. MAE (Mean Absolute Error)
- 의미 : 예측값과 실제값의 평균적인 차이
- 값이 작을수록 좋음.
📍해석
- 레코드가 적을 때 : 오차가 370 → 예측이 매우 부정확
- 레코드가 많을 때 : 오차가 13.8 → 훨씬 정밀한 예측
즉, 데이터가 많아질수록 모델의 평균 오차가 급감했다는 의미
2. R² (결정계수)
- 의미 : 모델이 실제 데이터를 얼마나 잘 설명하는가 (0~1 사이)
- 1에 가까울수록 좋고, 음수가 나오면 모델이 무의미하다는 뜻
📍해석
- 레코드가 적을 때 : R² = -0.04 → 모델이 데이터를 전혀 설명하지 못함 (평균값으로 찍는 것보다 못함)
- 레코드가 많을 때 : R² = 0.8167 → 모델이 약 81.7%의 변동을 설명함, 꽤 잘 맞는 모델
3. 종합 해석
데이터(레코드)가 많아질수록 회귀모델의 성능이 안정되고 예측력이 크게 향상됨
- 표본이 작을 땐, 편향(bias)과 분산(variance)이 커서 모델이 불안정함
- 표본이 충분해지면, 노이즈가 평균화되어 일반화 성능이 향상
실제 데이터 연습.
# 기존 코드 복습용
import pandas as pd # 표 형태 데이터(컬럼/행) 처리용
import lightgbm as lgb # 트리 기반 부스팅 모델(LightGBM)
from sklearn.model_selection import train_test_split # 학습/평가 데이터 분리
from sklearn.metrics import mean_absolute_error, r2_score # 회귀 평가 지표(MAE, R^2)
# 데이터 로드
df = pd.read_csv("2025-10-22.csv") # CSV 파일을 데이터프레임으로 불러옴
# 파생 변수
df["CTR"] = df["clicks"] / df["impressions"] # CTR=클릭/노출 (노출 0이면 무한대 위험)
df["CVR"] = df["conversions"] / df["clicks"].replace(0, 1) # CVR=전환/클릭. 클릭이 0이면 1로 바꿔 나눔(수학적 왜곡 발생 가능)
df["CPA"] = df["spend"] / df["conversions"].replace(0, 1) # CPA=비용/전환. 전환 0이면 1로 바꿔 비용 그대로가 됨(의미 왜곡)
# 특징, 타깃 분리
X = df[["spend", "impressions", "clicks", "CTR", "CVR"]] # 입력 변수(특징)
y = df["CPA"] # 예측 대상(타깃): 획득 단가
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split( # 홀드아웃 방식 분할
X, y, test_size=0.2, random_state=42 # 테스트 20%, 재현성 위해 시드 고정
)
# 모델 학습
model = lgb.LGBMRegressor( # 회귀용 LightGBM 모델
num_leaves=31, # 단일 트리 복잡도(잎 수). 클수록 표현력↑ 과적합 위험↑
learning_rate=0.05, # 학습률(작을수록 안정, 학습 오래 걸림)
n_estimators=200 # 부스팅 트리 개수(많을수록 표현력↑ 과적합 가능)
)
model.fit(X_train, y_train) # 모델 파라미터 학습
# 평가
y_pred = model.predict(X_test) # 테스트셋 예측
print("MAE:", mean_absolute_error(y_test, y_pred)) # 평균 절대 오차(작을수록 좋음)
print("R²:", r2_score(y_test, y_pred)) # 결정계수(1에 가까울수록 좋고, 음수면 평균보다 못함)# 실제 집행 데이터 연습용
# CPC 예측 (CTR 포함 버전)
# 입력: gender, impressions, spend, clicks, CTR
# 출력: 예측 CPC (KRW)
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import OneHotEncoder
# ------------------------------
# 1) 데이터 로드
# ------------------------------
df = pd.read_csv("2025-10-22.csv")
# ------------------------------
# 2) 파생 변수 생성
# ------------------------------
# CTR이 없으면 계산
if "CTR" not in df.columns:
df["CTR"] = np.where(df["impressions"] > 0, df["clicks"] / df["impressions"], 0.0)
# CPC 타깃 변수 (전환 아님, 클릭 기준)
df["CPC"] = np.where(df["clicks"] > 0, df["spend"] / df["clicks"], np.nan)
df = df.dropna(subset=["CPC"]) # 클릭 0 → 예측 불가
# ------------------------------
# 3) 특징 / 타깃 분리
# ------------------------------
X = df[["gender", "impressions", "spend", "clicks", "CTR"]].copy()
y = df["CPC"].copy()
# ------------------------------
# 4) 결측 처리 & 인코딩
# ------------------------------
X["gender"] = X["gender"].fillna("Unknown")
# 원-핫 인코딩 (성별)
try:
enc = OneHotEncoder(handle_unknown="ignore", sparse_output=False)
except TypeError:
enc = OneHotEncoder(handle_unknown="ignore", sparse=False)
g = enc.fit_transform(X[["gender"]])
g_cols = [f"gender_{cat}" for cat in enc.categories_[0]]
g_df = pd.DataFrame(g, columns=g_cols, index=X.index)
# 합치기
X = pd.concat([g_df, X.drop(columns=["gender"])], axis=1)
# ------------------------------
# 5) 데이터 분리
# ------------------------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ------------------------------
# 6) LightGBM 학습
# ------------------------------
model = lgb.LGBMRegressor(
num_leaves=31,
learning_rate=0.05,
n_estimators=300,
random_state=42
)
model.fit(X_train, y_train)
# ------------------------------
# 7) 평가
# ------------------------------
y_pred = model.predict(X_test)
print(f"MAE: {mean_absolute_error(y_test, y_pred):.2f}")
print(f"R²: {r2_score(y_test, y_pred):.4f}")
# ------------------------------
# 8) 예측 함수
# ------------------------------
def predict_cpc(gender: str, impressions: int, spend: float, clicks: int, ctr: float):
# 입력을 DataFrame으로 변환
row = pd.DataFrame([{
"gender": gender,
"impressions": impressions,
"spend": spend,
"clicks": clicks,
"CTR": ctr
}])
# 성별 인코딩 적용
g_row = enc.transform(row[["gender"]])
g_row = pd.DataFrame(g_row, columns=g_cols)
row_ = pd.concat([g_row, row.drop(columns=["gender"])], axis=1)
# 예측
pred_cpc = float(model.predict(row_)[0])
return pred_cpc
# ------------------------------
# 9) 콘솔 입력 예시
# ------------------------------
# g = input("성별을 입력하세요 (Male/Female): ").strip()
# imp = int(input("노출수를 입력하세요: "))
# s = float(input("지출 금액(KRW): "))
# clk = int(input("클릭(전체): "))
# ctr = float(input("CTR(전체): "))
# result = predict_cpc(g, imp, s, clk, ctr)
# print(f"\n예측된 CPC: {result:.2f} KRW")
XGBoost (Extreme Gradient Boosting)
- Gradient Boosting 알고리즘을 효율적이고 정확하게 개선한 버전
- 트리 기반 모델 중 가장 널리 쓰이는 예측 성능이 높은 앙상블 학습기법
- 핵심 목표 : 빠르고 정확하고 과적합이 적은 Boosting 모델 구현
- 주요 활용 : 광고 성과 예측, 신용 평가, 고객 이탈 예측, 이미지 분류 등

1. Boosting이란?
| 구분 | 내용 |
| Ensemble(앙상블) | 여러 개의 약한 모델(weak learners)을 결합하여 강력한 모델(strong learner)을 만드는 방법 |
| Boosting | 이전 모델의 오차를 보완하는 방향으로 다음 모델을 학습시키는 방법 |
| Gradient Boosting | 오차(잔차)를 경사하강법(Gradient Descent) 개념으로 최적화하는 부스팅 방식 |
- 잘못 예측한 데이터에 집중하면서 점점 더 성능을 향상시키는 방식
2. 학습 원리
- 의사결정 나무를 여러 개 결합
- 각 트리는 이전 트리의 예측 오차를 줄이도록 학습하며 최종 예측은 모든 트리의 예측값을 가중합한 결과
1. 예측 함수

2. 목적 함수
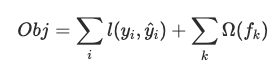
3. 주요 특징
| 특징 | 설명 |
| Regularization (정규화) | 트리의 복잡도를 제어하여 과적합 방지 |
| Shrinkage (Learning Rate) | 각 트리의 기여도를 줄여 점진적으로 학습 |
| Column Subsampling | 변수 일부만 사용 → 과적합 감소, 계산 속도 향상 |
| Handling Missing Data | 결측값을 자동으로 처리 (분기 시 최적 방향 선택) |
| Parallel Processing | 여러 트리를 병렬 학습 (CPU 멀티스레딩 지원) |
| Early Stopping | 검증 손실이 줄지 않으면 학습 조기 종료 |
| Tree Pruning (후방 가지치기) | 손실 개선이 없는 가지 제거로 효율적 트리 구성 |
4. 다른 알고리즘과의 비교
| 비교 항목 | Gradient Boosting | Random Forest | XGBoost |
| 학습 방식 | 순차적 (이전 트리 오차 보완) | 병렬적 (독립 트리 학습) | 순차 + 병렬 최적화 |
| 과적합 제어 | 약함 | 비교적 강함 | 정규화로 매우 강함 |
| 속도 | 느림 | 빠름 | 매우 빠름 |
| 성능 | 높음 | 보통 | 매우 높음 |
| 하이퍼파라미터 | 많음 | 적음 | 많지만 성능 조정 폭 넓음 |
5. 주요 하이퍼파라미터
| 파라미터 | 의미 | 설명 |
| n_estimators | 트리 개수 | 많을수록 성능↑, 과적합 위험 |
| learning_rate | 학습률 | 낮을수록 안정적 (0.01~0.1 권장) |
| max_depth | 트리 깊이 | 깊을수록 복잡도↑ |
| subsample | 샘플 비율 | 0.8~1.0 권장 |
| colsample_bytree | 변수 샘플링 비율 | 과적합 방지용 |
| lambda, alpha | L2, L1 정규화 계수 | 과적합 억제 |
| min_child_weight | 리프 노드 최소 가중치 | 과적합 방지 |
6. 장점과 한계
- 장점 : 높은 예측 정확도, 과적합 방지, 결측치 처리, 속도 빠름
- 한계 : 파라미터 많음 → 튜닝 필요, 해석력 낮음 (블랙박스)
7. CPA 예측 적용 예시
- 입력 : 광고비, 노출수, 클릭수, CTR, CVR, 캠페인 유형, 요일, 시간대
- 출력 : CPA
- 장점
- 광고 캠페인 간 비선형 관계 및 변수 상호작용 포착
- 정규화 기능으로 예산 과다·소수 전환 등 노이즈 완화
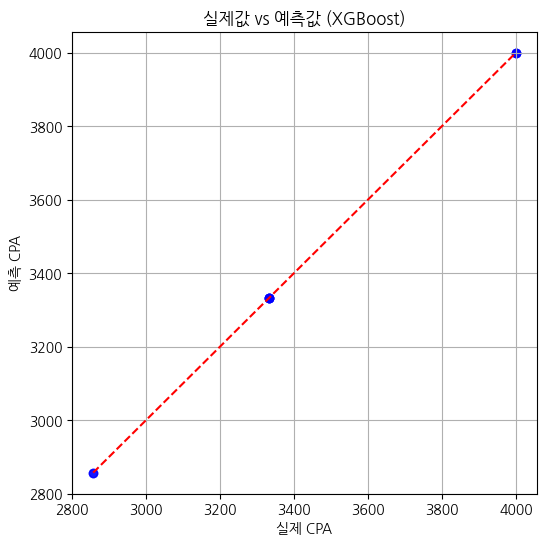
- 피처 중요도(Feature Importance)를 통해 CPA 영향 요인 분석 가능
8. 예시 코드

연습 1. 다채널 광고 데이터를 활용한 ROAS 예측 모델 구축
광고비, 노출수, 클릭수, 전환수, 채널, 광고유형 등의 과거 데이터를 활용해 ROAS(광고수익률)을 예측하는 회귀 모델 개발
1. 과정 정리
| 단계 | 설명 | 학습 포인트 |
| ① 데이터 로드 | CSV 파일(ad_campaign_roas_data.csv)을 Pandas로 불러옴 | 데이터 구조 이해 |
| ② 데이터 탐색 및 전처리 | 결측치, 이상치, 형 변환, 로그변환, 범주형 인코딩 등 | 실제 마케팅 데이터엔 결측과 스케일 차가 흔함 |
| ③ 특징 및 타깃 설정 | 입력(X): 광고비, 노출수, 클릭수, 채널 등 / 타깃(y): ROAS | 예측 목표 정의가 가장 중요 |
| ④ 학습/테스트 분리 | train_test_split으로 8:2 분할 | 과적합 방지, 모델 검증 기반 마련 |
| ⑤ XGBoost 회귀모델 학습 | XGBRegressor()로 모델 학습 | 부스팅 개념 이해 (트리 앙상블) |
| ⑥ 모델 평가 | MAE, RMSE, R² 계산 | 모델의 성능을 수치로 평가 |
| ⑦ 특징 중요도 분석 | 어떤 요인이 ROAS에 가장 큰 영향? | 마케터 관점에서 핵심 인사이트 |
| ⑧ 예측 코드 작성 | 새로운 캠페인 입력값 → 예측된 ROAS 출력 | 실무 적용 단계 |
| ⑨ 최종 결과 요약 | 지표, 중요 변수, 개선 아이디어 정리 | 보고서형 사고 훈련 |
2. XGBoost 작동 원리 복습
- 첫 번째 트리가 데이터의 기본 패턴 학습
- 두 번째 트리는 첫 번째 트리의 오류(잔차) 학습
- 세 번째 트리는 앞선 두 개의 합의 부족한 부분 보완 → 이렇게 여러 트리를 반복적으로 추가하며 오차를 줄여나가는 방식
즉, XGBoost는 "잔차를 줄여가는 앙상블" → "Residual Learning"이라는 개념이 여기서도 그대로 등장
3. 평가 지표 해석
| 지표 | 의미 | 좋은 방향 |
| MAE (Mean Absolute Error) | 실제값과 예측값의 절댓값 차이 평균 | 낮을수록 좋음 |
| RMSE (Root Mean Squared Error) | 큰 오차에 더 민감한 지표 | 낮을수록 좋음 |
| R² (결정계수) | 모델이 데이터를 얼마나 설명하는가 (0~1) | 1에 가까울수록 좋음 |

4. 피처 중요도 (Feature Importance)
모델이 학습된 후,
- XGBoost는 각 피처가 예측에 기여한 정도를 계산할 수 있음
- model.feature_importances_ 또는 plot_importance(model)으로 시각화 가능
| 변수 | 중요도 | 해석 |
| ad_spend | 0.42 | 광고비가 ROAS에 가장 큰 영향 |
| clicks | 0.25 | 클릭수 변화가 ROAS 예측에 크게 기여 |
| channel_video | 0.18 | 영상 채널일수록 ROAS가 달라짐 |
| impressions | 0.10 | 노출량의 영향은 상대적으로 낮음 |
👉 이 단계가 바로 데이터 인사이트 도출
단순히 예측 모델이 아니라 "어떤 요인이 효율을 결정짓는가?"를 찾는 것이 마케팅 분석의 핵심


연습 2. 광고 유형별 CTR 예측 모델 구축
광고유형, 채널, 노출수, 광고비 등 데이터를 활용해 CTR을 예측하고 클릭률에 영향을 주는 요인 규명
A. 입력 변수를 모두 다 사용했을 때



B. 4개의 변수만 사용했을 때



연습 3. 광고비 대비 성과 예측을 통한 예산 최적화 모델
현재 캠페인 데이터를 기반으로 광고비 수준별 ROAS 변화를 예측하고 최적 광고비 수준 제시
A. 하이퍼파라미터 튜닝 전
===== 모델 성능 평가 =====
MAE (평균절대오차): 0.12
RMSE (제곱근평균제곱오차): 0.18
R² (결정계수): 0.966
# 하이퍼파라미터 튜닝 진행
from sklearn.model_selection import GridSearchCV
import xgboost as xgb
# 튜닝할 하이퍼파라미터와 탐색할 값의 범위 정의
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.05, 0.1],
'max_depth': [3, 4, 5],
'subsample': [0.8, 1.0],
'colsample_bytree': [0.8, 1.0],
}
# XGBoost 회귀 모델 객체 초기화
xgb_model = xgb.XGBRegressor(objective='reg:squarederror', random_state=42)
# GridSearchCV 객체 생성
grid_search = GridSearchCV(
estimator=xgb_model,
param_grid=param_grid,
scoring='r2', # 평가 지표: 결정계수
cv=5, # 교차 검증 폴드 수
verbose=1, # 진행 상황 출력
n_jobs=-1 # 사용 가능한 모든 코어 사용
)
# 학습 데이터에 대해 그리드 서치 수행
grid_search.fit(X_train, y_train)
# 최적의 하이퍼파라미터 및 교차 검증 점수 출력
print("===== 최적 하이퍼파라미터 =====")
print(grid_search.best_params_)
print(f"Best R² Score (Cross-validation): {grid_search.best_score_:.3f}")
# 최적의 모델 저장
best_model = grid_search.best_estimator_
print("\n최적의 모델이 best_model 변수에 저장되었습니다.")
B. 하이퍼파라미너 튜닝 후
===== 최적 모델 성능 평가 =====
MAE (평균절대오차): 0.09
RMSE (제곱근평균제곱오차): 0.14
R² (결정계수): 0.981
===========================



XGBoost 알고리즘 분야별 모델 구축 연습


| 분야 | 검색 키워드 예시 | 주요 항목 | 예측 타깃 |
| 1. 음료가격 추세 | “코카콜라 330ml 캔 2000~2024년 가격” | 연도, 가격 | 향후 소비자가격 예측 |
| 2. 부동산 시장 | “서울 아파트 평균 매매가 연도별 2000~2024” | 연도, 평균가격 | 향후 주택가격 예측 |
| 3. 환율 추세 | “달러-원 환율 연도별 평균 (2000~2024)” | 연도, 평균환율 | 내년도 환율 예측 |
| 4. 주식시장 | “삼성전자 연도별 주가 평균 2000~2024” | 연도, 평균주가 | 향후 주가 예측 |
| 5. 경제지표 | “한국 GDP 성장률 1990~2024” | 연도, 성장률(%) | 향후 성장률 예측 |
| 6. 유가 | “국제유가(브렌트유) 연도별 평균 1990~2024” | 연도, 유가(USD) | 향후 유가 예측 |
| 7. 물가 | “한국 소비자물가 상승률 연도별 1990~2024” | 연도, 물가상승률 | 인플레이션 예측 |
| 8. 기후 데이터 | “서울 연도별 평균기온 (1980~2024)” | 연도, 평균기온 | 향후 기온 예측 |
| 9. 브랜드 매출 | “스타벅스 연도별 매출액 (2000~2024)” | 연도, 매출액 | 향후 매출 추세 예측 |
| 10. 영화산업 매출 | “한국 박스오피스 총매출 연도별 2000~2024” | 연도, 매출액 | 산업규모 예측 |
실습 1. 음료 가격 추세 (코카콜라 330ml 가격)
A. 1차 모델 생성 시도
MAE (평균절대오차): 120.06
RMSE (제곱근평균제곱오차): 141.47
R² (결정계수): -2.574


B. 2차 모델 생성 시도
Mean Squared Error (MSE): 1.3377781549195333e-08
R-squared (R2): 1.0

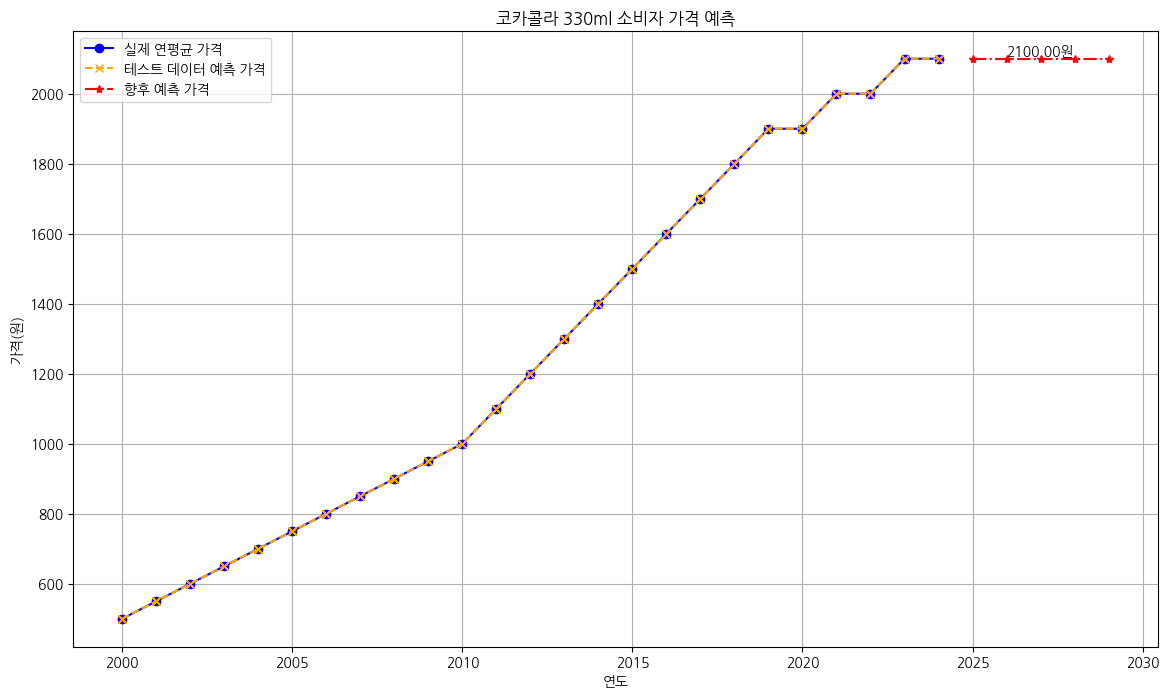
실습 2. 부동산 시장 (서울 아파트 평균 매매가)
Mean Squared Error (MSE): 0.2051395428355251
R-squared (R2): 0.9872438350142072
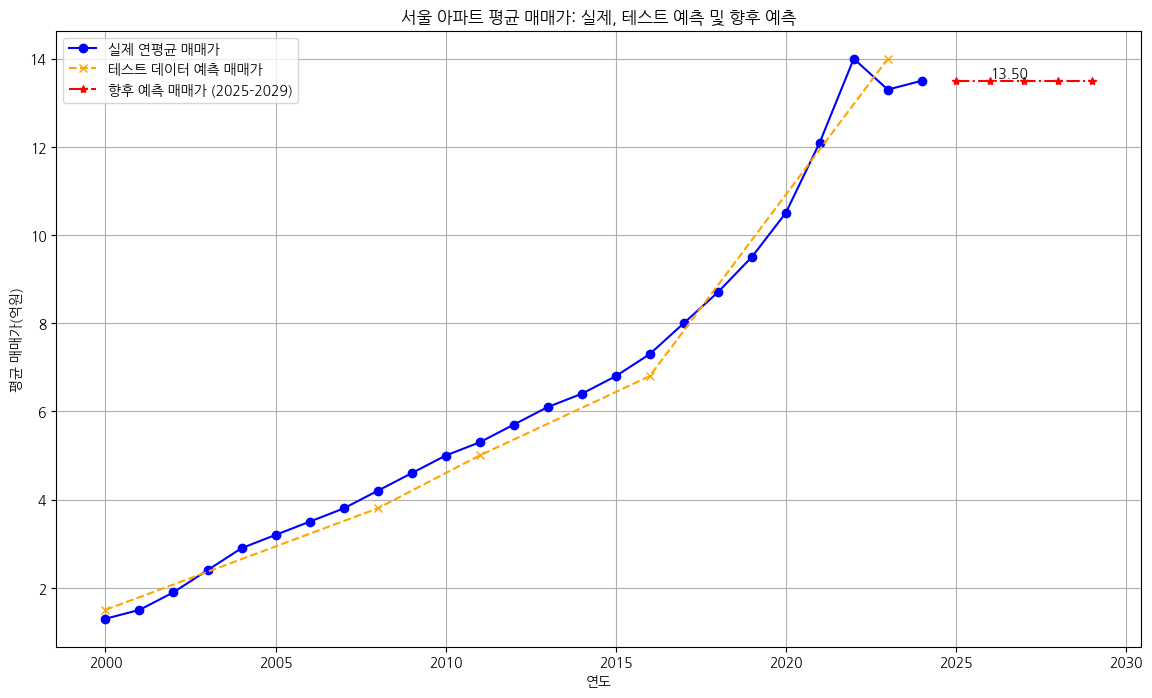
실습 3. 환율 추세 (달러-원 환율 평균)
Mean Squared Error (MSE): 11635.66941129871
R-squared (R2): -1.0091867912630033

| 시기 | 주요 사건 | 환율 반응 및 특징 |
| 2000~2002 | 닷컴 버블 붕괴, 9·11 테러 | 세계 경기 둔화로 안정세를 보이다가 급등세로 전환함 (달러 강세, 원화 약세) |
| 2003~2007 | 유가 상승 및 무역 흑자 | 수출 호조와 외자 유입으로 원화 강세가 지속되어 환율이 900원대까지 하락 |
| 2008~2009 | 글로벌 금융위기 (서브프라임 모기지 사태) | 리먼 브라더스 파산 후 환율이 1,500원대까지 급등하며 외환보유고 감소 |
| 2010~2013 | 글로벌 경기 회복, 유럽 재정위기 | 자본 유입과 한국의 안정적 펀더멘털로 환율 안정세 유지 (1,100원대) |
| 2015~2016 | 미국 금리 인상, 중국 경기 둔화 | 달러 강세 영향으로 환율이 다시 1,200원대로 상승 |
| 2017~2019 | 한반도 지정학적 긴장 완화, 무역전쟁 | 북미 정상회담 등으로 원화 강세, 그러나 미·중 무역분쟁으로 변동성 확대 |
| 2020~2021 | COVID-19 팬데믹 | 글로벌 경제 불확실성으로 환율 급등 (1,200~1,300원대) |
| 2022 | 러시아-우크라이나 전쟁, 미 연준 금리 급등 | 원자재 가격 폭등과 미국 금리 인상으로 달러 가치 상승, 환율 1,400원대 돌파 |
| 2023~2024 | 트럼프 대통령 재선, 미 금리 인하 지연, 국제 불안 확대 | 달러 강세 지속과 국내 경기 둔화로 원/달러 환율이 1,360~1,470원까지 상승 |
- 수치 변화에 영향을 주는 사건이나 맥락까지 함께 고려해야 하는 데이터의 경우 정성적 요인 반영 필요
- 환율과 같은 거시경제 데이터는 단순 시계열 수치뿐 아니라 당시 주요 사건·정책·사회적 이슈와 같은 비정형 맥락 데이터를 함께 반영해야 함 → 이를 통해 모델은 단순 패턴이 아닌 상황적 요인까지 학습할 수 있음
실습 4. 주식시장 (삼성전자 주가 평균)
Mean Squared Error (MSE): 62733734.66014961
R-squared (R2): 0.9313209488083608

실습 7. 물가 (한국 소비자물가 상승률)
A. 하이퍼파라미터 튜닝 전
Mean Squared Error (MSE): 1.859860737566337
Root Mean Squared Error (RMSE): 1.3637671126575597
R-squared (R2): -0.2716996496180082

B. 하이퍼파라미터 튜닝 후
Mean Squared Error (MSE): 1.4910759041658517
Root Mean Squared Error (RMSE): 1.2210961895632348
R-squared (R2): -0.019539079771522472

실습 9. 브랜드 매출 (스타벅스 매출액)
Mean Squared Error (MSE): 1.4711440233484632
Root Mean Squared Error (RMSE): 1.2129072608194178
R-squared (R2): 0.9876041874251403

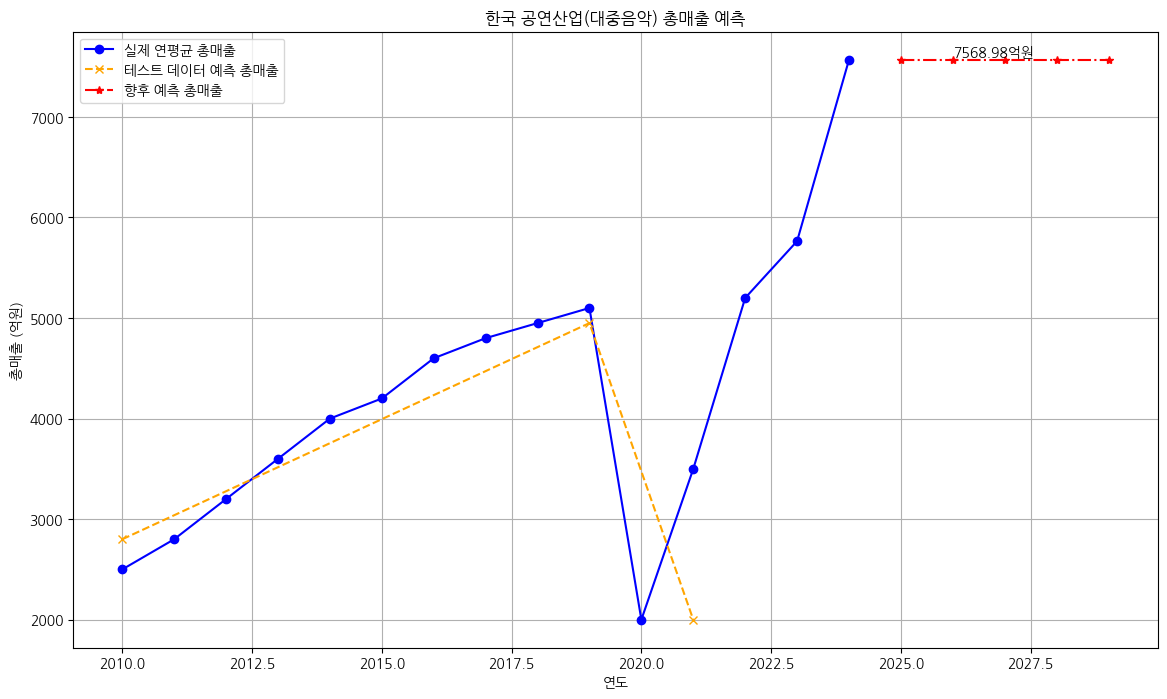
실습 10. (응용) 공연 산업 매출 (대중음악 중 콘서트 장르 연도별 매출로 산업규모 파악)
Mean Squared Error (MSE): 787500.6875
Root Mean Squared Error (RMSE): 887.4123548272246
R-squared (R2): 0.3132261633872986
시나리오 1. XGBoost를 이용한 광고 캠페인 CPA 예측 및 예산 최적화
- 배경 : 마케팅 부서는 Google, Meta, TikTok 등 여러 채널에 광고비를 투입 중이나 채널별 전환 효율의 편차가 커서 최적화가 필요함
- 문제 정의 : 동일 예산이라도 CPA가 낮은 채널이 더 효율적 → 이를 데이터 기반으로 예측하여 ROI 극대화
- 모델 선택 이유 : XGBoost는 비선형 관계, 변수 간 상호작용, 정규화를 통한 과적합 방지에 강점을 가지고 있음
1. CPA 예측 모델
===== 모델 성능 평가 =====
MAE : 285.27
RMSE : 593.61
R² : 0.941


2. 마케팅 인사이트
| 구분 | 분석 결과 | 마케팅적 시사점 |
| 모델 성능 | R² = 0.94 → 모델이 CPA 변동의 94%를 설명 | 매우 높은 설명력으로 충분히 실무 적용 가능한 수준의 예측력 |
| 주요 변수 | Conversions > CVR > Spend > Clicks 순 | 전환수가 CPA에 가장 큰 영향을 미치며 전환 효율 중심 설계 필요 |
| 저효율 캠페인 | TikTok 채널에서 상대적으로 CPA가 높게 나타남 | Meta·Google 중심으로 예산 재분배 필요 |
| 성과 예측 | 예측된 CPA 기반 캠페인 효율 등급화 가능 | 고효율 캠페인 유지, 저효율은 조기 중단 및 최적화 권장 |
| 자동화 가능성 | 일 단위 로그 데이터에 모델 적용 가능 | Looker Studio / Flask 대시보드로 실시간 모니터링 가능 |
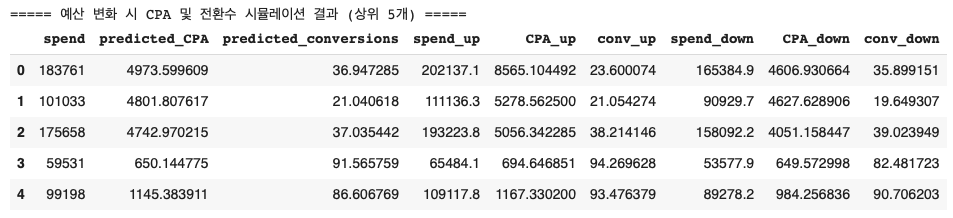
시나리오 2. XGBoost 예측 모델을 이용한 예산 10% 증감 시 예상 CPA 및 전환수 변동 분석
# 코드 일부 추출
df["predicted_CPA"] = model.predict(X)
df["predicted_conversions"] = df["spend"] / df["predicted_CPA"]
# 예산 +10%, -10% 상황 시뮬레이션
df["spend_up"] = df["spend"] * 1.10
df["spend_down"] = df["spend"] * 0.90
# 기존 입력값을 복사하여 시뮬레이션용 데이터 생성
X_up = X.copy()
X_up["spend"] = df["spend_up"]
df["CPA_up"] = model.predict(X_up)
df["conv_up"] = df["spend_up"] / df["CPA_up"]
X_down = X.copy()
X_down["spend"] = df["spend_down"]
df["CPA_down"] = model.predict(X_down)
df["conv_down"] = df["spend_down"] / df["CPA_down"]

시나리오 요점 정리
- XGBoost 모델은 단순 CPA 예측을 넘어 예산 시뮬레이션 기반 Growth Strategy Tool로 발전 가능
- 데이터를 기반으로 예산의 “효율적 구간”을 파악하여 ROI를 극대화하는 예산 배분 전략 수립 가능
- 일 단위로 모델을 업데이트하면 실시간 캠페인 효율 자동 진단 시스템 구축 가능
시나리오 3. XGBoost 기반 웹 대시보드


✏️ 개인 회고
흠 모델 생성 실습 자체는 분명 재밌는데, 하나하나의 원리를 파악하는 과정이 매우 어렵다
이론을 완벽하게 이해하고 싶은데 통계 기초의 개념이 아직 온전히 잡혀있지 않아 단어 하나에 막히는 것 같기도 하고 ..
어떻게 하면 효과적으로 공부할 수 있을지 잘 모르겠고만 ... 그냥 계속 눈으로 보고 익히는 수밖에 없으려나
통계와 머신러닝 챕터를 지나오면서 나 자신한테 느끼는 답답함이 너무 크다 한계를 좀 깨부수고 싶다 🥲